Optimised UUIDs in mysql
Written on 2017-11-29At Spatie, we're working on a large project which uses UUIDs in many database tables. These tables vary in size from a few thousand records to half a million.
As you might know, normal UUIDs are stored as CHAR(36) fields in the database.
This has an enormous performance cost, because MySQL is unable to properly index these records.
Take a look at the following graph, plotting the execution time of hundred queries against two datasets: one with 50k rows, one with 500k rows.
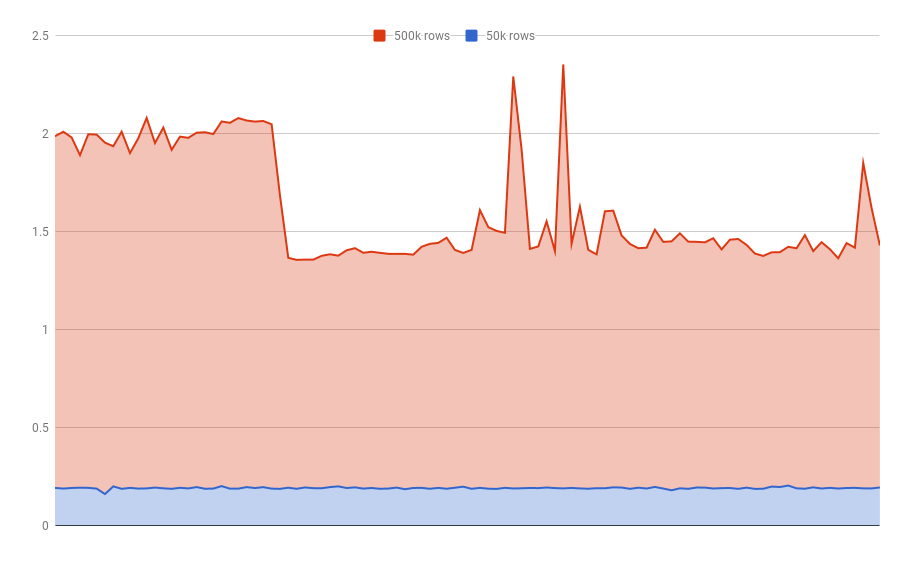
That's an average of more than 1.5 seconds when using textual UUIDs!
There's an important edit here: the benchmark above was performed on un-indexed fields. I've since changed the benchmark results to work with indexed textual fields for a more fair comparison. There's still a performance gain to not using textual UUIDs, so keep reading!
Looking around for better alternatives, we found a two-part solution.
Saving UUIDs as binary data
Instead of saving UUIDs as CHAR, it's possible to store their actual binary data in a BINARY field.
Storing them in this format, MySQL has a lot less trouble indexing this table.
This is the graph plotting a much faster result.
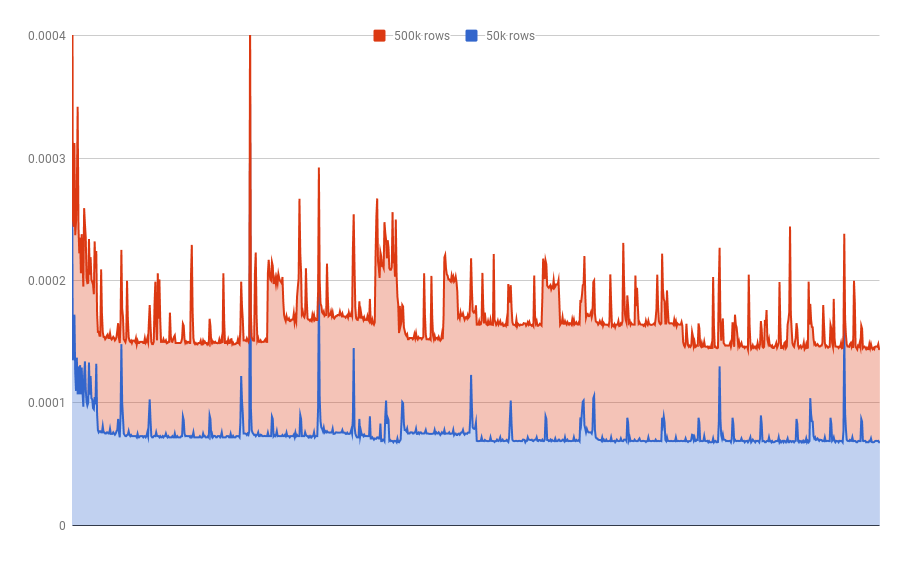
That's an average of 0.00008832061291 seconds per query,
in comparison to 1.5 0.0001493031979 seconds for the indexed textual UUID.
It becomes even better!
The binary encoding of UUIDs solved most of the issue. There's one extra step to take though, which allows MySQL to even better index this field for large datasets.
By switching some of the bits in the UUID, more specifically time related data, we're able to save them in a more ordered way. And it seems that MySQL is especially fond of ordered data when creating indices. There's one important thing to note: this time related bits are only available in UUID version 1.
Using this approach, we can see following result.
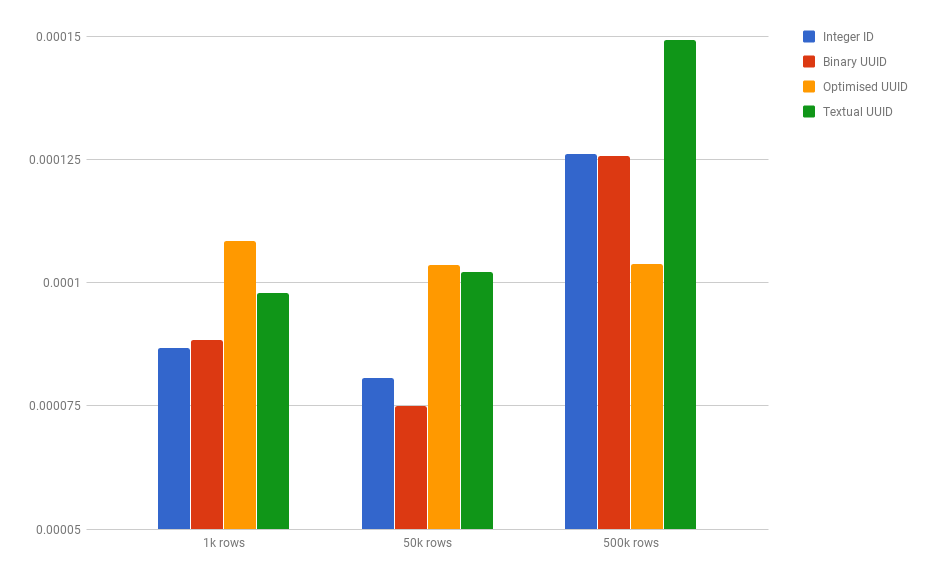
The optimised approach is actually slower for lookups in a small table,
but it outperforms the normal binary approach on larger datasets.
It even performs better than an AUTO_INCREMENT integer ID!
But as you can see, we need very large tables before the optimised UUID has a benefit.
I would recommend only using UUIDs when there's a very good use case for them. For example: when you want unique IDs over all tables, and not just one; or if you want to hide exactly how many rows there are in the table.
The MySQL team wrote a blogpost explaining this bit-shifting of UUIDs in further detail. If you'd like to know how it works internally, over there is a good start.
If you're building a Laravel application and would like to use optimised UUIDs in your project, we've made a package especially for you. You'll also find more benchmark details in the README over there.
Finally, if you're looking into implementing this behaviour in a non-Laravel project, you should definitely take a look at Ramsey's UUID package, we're using it too!
