Asynchronous PHP
Written on 2017-12-24We're working on a new package at Spatie. It's called spatie/async and meant to do asynchronous parallel processing in PHP.
Parallel processing in PHP might seem like an edge case for many web developers, but let's take a look at a few use-cases we see at Spatie:
- Image optimisation
- PDF rendering
- Concurrent site crawling
- Code generators
- Static site generators - like Stitcher
We wanted to create an easy-to-use package, yet one that could solve our use cases.
Some of the examples listed above will not use the new spatie/async package,
because there's also a queueing system provided with Laravel.
This is how asynchronous code with our package looks like.
use Spatie\Async\Process; $pool = Pool::create(); foreach (range(1, 5) as $i) { $pool[] = async(function () use ($i) { // Something to execute in a child process. })->then(function (int $output) { // Handle output returned from the child process. })->catch(function (Exception $exception) { // Handle exceptions thrown in the child process. }); } await($pool);
Outperforming Amp? Not quite yet.
If you're into parallel PHP, you've probably heard of Amp and ReactPHP. Our package aims not to compete with those two, as it only solves one tiny aspect of parallelism in PHP; and tries to solve it in a different way.
We did however run some benchmarks to compare our package performance against Amp. Special thanks to Niklas Keller, one of the developers of Amp. He pointed out some mistakes in our previous benchmarks, and helped making them more fair.
The new benchmarks compare a few scenarios.
The first two groups plot the execution time of an empty process,
while the third and fourth groups show the execution time of processes with a different time to finish,
using several sleep intervals.
Between the two groups, we're also comparing a capped concurrency configuration and a non-capped configuration.
Capped means that there are more processes than the pool can execute at once.
The benchmark code can be found here.
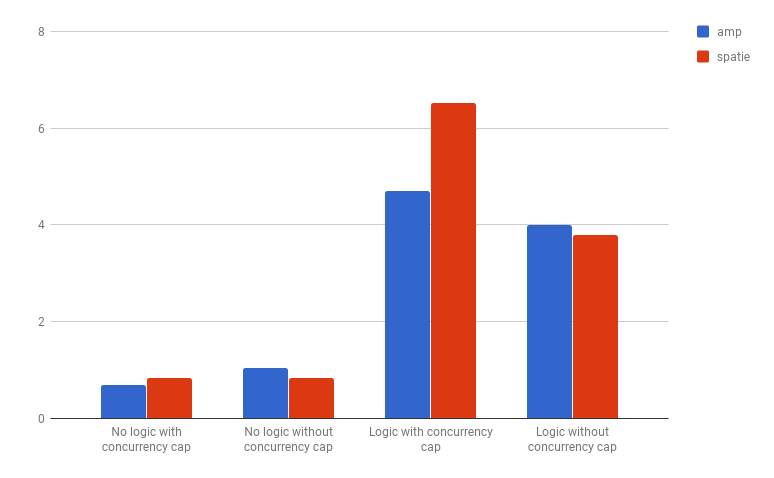
I tried to draw a few conclusions from these test.
- Real life processes take time to run and finish.
For our use-cases, the "with logic" benchmarks are more relevant. - Regarding process execution time, it seems like our package has less overhead: as long as the pool doesn't have to manage concurrency, we're finishing faster. - In real life applications though, the maximum concurrency setting will most likely be in effect, so it's clear that we'll need to improve that part of our codebase if we want better performance compared to Amp.
What about ReactPHP?
We've excluded ReactPHP from the benchmarks, because it's not a fair comparison.
ReactPHP doesn't allow to run closures or Tasks as sub-processes the way Amp and our package do.
With ReactPHP, you're working with plain processes, so there's no way to compare to it.
About process signals
The biggest difference between our package and Amp is the way of communicating between processes. We're solely relying on process signals to determine when a process is finished. It allows for less overhead, but also excludes Windows as a target platform.
Processes in UNIX systems can send signals to each other.
Depending on what kind of signal is received, a process will act different.
Signals are handled by the kernel, so they are pretty low level.
Before PHP 7.1 though, you had to declare(ticks=1) to use asynchronous signals in a reliable way.
This means that PHP will check for signals much more often, but it also introduces a lot of overhead:
A tick is an event that occurs for every N low-level tickable statements executed by the parser within the declare block. The value for N is specified using ticks=N within the declare block's directive section.
With PHP 7.1, there's a new way of handling interrupts sent by the kernel.
Zend Engine in PHP 7.1 was extended with ability of safe time-out and interrupt handling. Actually, PHP VM checks for EG(vm_interrupt) flag on each loop iteration, user function entry or internal function exit, and call callback function if necessary.
By using pcntl_async_signals(true), PHP will now check for signals in a much more performant way.
A more in-depth explanation can be found in the rfc,
submitted by Dmitry Stogov.
It's thanks to this mechanism that we're able to act on process status changes in a real asynchronous way, without having to rely on sockets or process status polling.
